
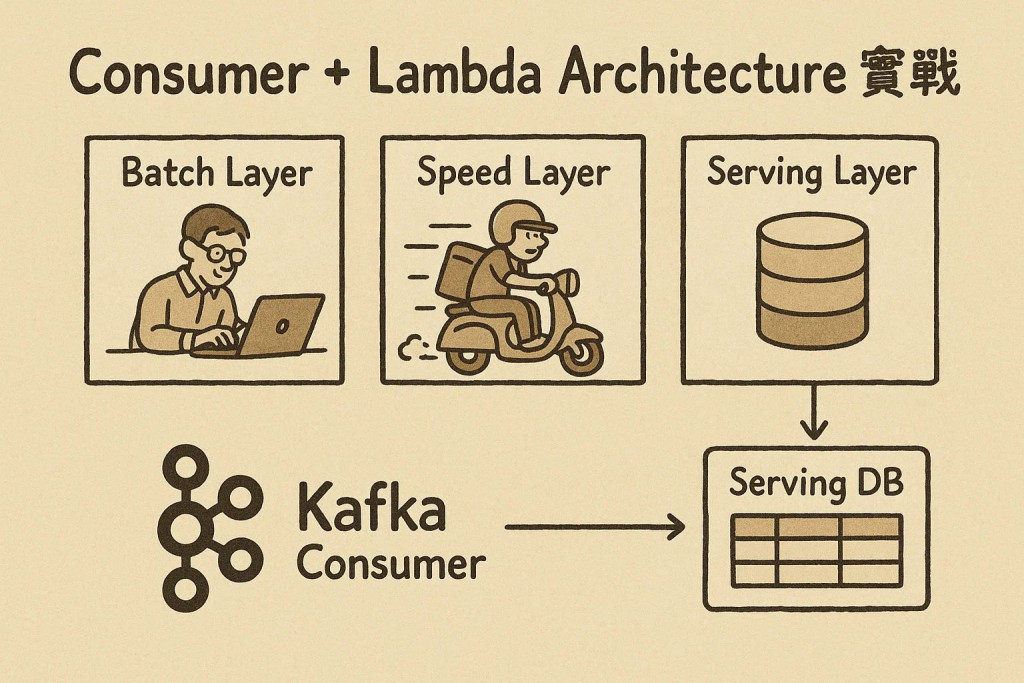
在上一篇我們聊過 Lambda Architecture 的三個層:
今天開始,我們要深入 Speed Layer 的實作世界。接下來的系列將專注於 Speed Layer 相關的實作技術,從手寫 Kafka Consumer 開始,逐步探索 Stream Processing 的核心機制。
我們要實作 Speed Layer 的關鍵組件 - 寫一個 Kafka Consumer,負責即時接收訂單資料,送進 Serving DB。Batch Layer 則專心處理每天的歷史全量數據。
平常我們用各種強大的框架解決問題,但有沒有想過:
很多時候,我們只是知其然(知道怎麼用),但不知其所以然(不知道為什麼)。
通過手寫最基礎的程式碼,我們能真正理解工具背後的邏輯。當你明白原理後,用任何工具都會更得心應手,除錯也更有方向感。
這就是這個系列的初衷:從最簡單的程式碼開始,一步步理解複雜系統的設計思路。
重要提醒
本文所有程式碼皆為教學與概念演示用的 Pseudo Code,可以幫助你理解並解決實際場景的問題,但這裡的程式碼不能直接使用,主要目的是用來講解 Stream Processing 的設計思路與核心概念。閱讀時建議把重點放在理解整體架構和設計邏輯上,程式碼細節部分可以輕鬆看過就好。
先看最簡單的版本:
from kafka import KafkaConsumer
import json
# 訂閱 orders topic
consumer = KafkaConsumer('orders')
print("[Speed Layer] Waiting for fresh orders...")
for message in consumer:
order = json.loads(message.value.decode('utf-8'))
insert_db(order)
conn.commit()
print(f"[Speed Layer] Inserted order {order['id']}")
這段邏輯很直覺:
這裡有兩張關鍵數據表:
orders_batch_summary - Batch Layer 每天計算好的歷史統計orders_realtime - Speed Layer 即時送達的訂單明細Dashboard 查詢時,會把兩張表合併計算,並且過濾掉 status = 'removed' 的無效訂單:
SELECT status, SUM(count) AS total
FROM (
SELECT status, count(*)
FROM orders_batch_summary
WHERE status != 'removed'
UNION ALL
SELECT status, COUNT(*) AS count
FROM orders_realtime
WHERE status != 'removed'
GROUP BY status
) t
GROUP BY status;
不過,隨著公司成長,Consumer 越來越多,每個人都自己撰寫邏輯,到最後程式碼變得錯綜複雜、難以維護。
我們需要重構 - 建立統一的 Stream Processing 架構,不再各自為政。
在團隊協作中,每個人都有自己的 Kafka Consumer 實作方式,導致程式碼風格不統一,整合困難。
解決方案是定義統一的「Source 介面」:
┌─────────────┐
│ BaseSource │ ◄── Abstract Interface
│ │
│ + run() │
└─────────────┘
△
│ implements
┌─────────────┐
│KafkaSource │ ◄── Concrete Implementation
│ │
│ + run() │
└─────────────┘
Step 1:定義 BaseSource 抽象介面
from abc import ABC, abstractmethod
class BaseSource(ABC):
def __init__(self, name: str):
self.name = name
@abstractmethod
def run(self):
pass
核心概念:
name 來識別run() 是抽象方法,強制子類實作Step 2:SimpleKafkaSource 初始化
class SimpleKafkaSource(BaseSource):
def __init__(self, name: str, topic: str, broker_address: str = "localhost:9092"):
super().__init__(name)
self.topic = topic
self.broker_address = broker_address
self.consumer = None
self.message_handler = self._default_handler
關鍵設計:
message_handler 可以替換,提供處理邏輯的彈性Step 3:設定 Kafka Consumer
def _setup_consumer(self):
self.consumer = KafkaConsumer(
self.topic,
bootstrap_servers=self.broker_address,
group_id=f"simple-source-{self.name}",
auto_offset_reset='latest',
value_deserializer=lambda m: json.loads(m.decode('utf-8')) if m else None
)
技術重點:
group_id 自動生成,避免衝突auto_offset_reset='latest' 從最新訊息開始消費Step 4:核心運行邏輯
def run(self):
self._setup_consumer() # 先設定 Consumer
for message in self.consumer: # 持續監聽訊息
self.message_handler({
'key': message.key,
'value': message.value,
'topic': message.topic,
'offset': message.offset
})
運行流程:
message_handler 處理訊息核心設計:Source 只負責接收資料,具體如何處理訊息則由外部注入的 message_handler 決定,這樣提供了處理邏輯的彈性。
import logging
import json
from abc import ABC, abstractmethod
from typing import Optional, Callable, Any
from kafka import KafkaConsumer
logger = logging.getLogger(__name__)
class BaseSource(ABC):
"""
基礎 Source 抽象類別
"""
def __init__(self, name: str):
self.name = name # Source 的唯一名稱
self._running = False # 運行狀態標誌
@abstractmethod
def run(self):
"""
主要運行方法,需要由子類實現
"""
pass
def stop(self):
"""
停止 Source
"""
self._running = False
logger.info(f"Source {self.name} stopped")
class SimpleKafkaSource(BaseSource):
"""
簡單的 Kafka Source 實現
"""
def __init__(
self,
name: str,
topic: str,
broker_address: str = "localhost:9092",
consumer_group: Optional[str] = None,
message_handler: Optional[Callable[[Any], None]] = None
):
super().__init__(name)
self.topic = topic # 要消費的 topic
self.broker_address = broker_address # Kafka broker 地址
self.consumer_group = consumer_group or f"simple-source-{name}" # 消費者群組
self.message_handler = message_handler or self._default_handler # 訊息處理函數
self.consumer: Optional[KafkaConsumer] = None # Kafka 消費者
def _default_handler(self, message):
"""
預設的訊息處理函數
"""
print(f"[{self.name}] Received message: {message}")
def _setup_consumer(self):
"""
設定 Kafka 消費者
"""
try:
self.consumer = KafkaConsumer(
self.topic,
bootstrap_servers=self.broker_address,
group_id=self.consumer_group,
auto_offset_reset='latest', # 從最新訊息開始消費
value_deserializer=lambda m: json.loads(m.decode('utf-8')) if m else None,
key_deserializer=lambda m: m.decode('utf-8') if m else None
)
logger.info(f"Consumer setup for topic: {self.topic}, group: {self.consumer_group}")
except Exception as e:
logger.error(f"Failed to setup consumer: {e}")
raise
def run(self):
"""
開始從 Kafka topic 讀取資料
"""
logger.info(f"Starting Source {self.name} for topic {self.topic}")
# 設定消費者
self._setup_consumer()
# 設定運行狀態
self._running = True
try:
# 主要消費迴圈
while self._running:
# 輪詢新訊息(1秒超時)
message_batch = self.consumer.poll(timeout_ms=1000)
# 處理每個分區的訊息
for topic_partition, messages in message_batch.items():
for message in messages:
if not self._running:
break
try:
# 處理訊息
self.message_handler({
'key': message.key,
'value': message.value,
'topic': message.topic,
'partition': message.partition,
'offset': message.offset,
'timestamp': message.timestamp
})
except Exception as e:
logger.error(f"Error processing message: {e}")
except KeyboardInterrupt:
logger.info("Received interrupt signal")
except Exception as e:
logger.error(f"Error in run loop: {e}")
finally:
# 清理資源
if self.consumer:
self.consumer.close()
logger.info(f"Source {self.name} finished")
def stop(self):
"""
停止 Source
"""
super().stop()
if self.consumer:
self.consumer.close()
在 Speed Layer 架構中,Source 負責數據輸入,Sink 則負責數據輸出。為了避免各種不統一的輸出實作,我們定義統一的 Sink 規格:
┌─────────────┐
│ BaseSink │ ◄── Abstract Interface
│ │
│ + write() │
└─────────────┘
△
│ implements
┌──────────────────┐
│SimplePostgreSQL │ ◄── Concrete Implementation
│Sink │
│ + write() │
└──────────────────┘
Step 1:定義 BaseSink 抽象介面
from abc import ABC, abstractmethod
class BaseSink(ABC):
def __init__(self, name: str):
self.name = name
@abstractmethod
def write(self, message):
pass
def setup(self):
pass # 預設空實作
核心概念:
name 來識別write() 是核心方法,處理實際的資料寫入setup() 提供預設實作,子類可覆寫Step 2:SimplePostgreSQLSink 初始化
class SimplePostgreSQLSink(BaseSink):
def __init__(self, name: str, host: str, dbname: str, table_name: str):
super().__init__(name)
self.host = host
self.dbname = dbname
self.table_name = table_name
self.connection = None
關鍵設計:
connection = None:需要時才建立連線Step 3:write 方法核心邏輯
def write(self, message):
# 自動偵測欄位並寫入資料庫
data = message.get('value', {})
# ... 動態生成 SQL 並執行插入
核心特色:自動偵測 message['value'] 的欄位結構,動態生成 INSERT SQL 並寫入資料庫。
這樣就完成了一個可自動適應不同資料結構的 Sink。
import logging
from abc import ABC, abstractmethod
from typing import Any, Dict
try:
import psycopg2
from psycopg2.extras import Json
from psycopg2 import sql
except ImportError:
psycopg2 = None
print("Warning: psycopg2 not installed. Run: pip install psycopg2-binary")
logger = logging.getLogger(__name__)
class BaseSink(ABC):
"""
基礎 Sink 抽象類別
"""
def __init__(self, name: str):
self.name = name
@abstractmethod
def write(self, message: Dict[str, Any]):
"""
寫入一個訊息
"""
pass
def setup(self):
"""
設定連接
"""
pass
def close(self):
"""
關閉連接
"""
pass
class SimplePostgreSQLSink(BaseSink):
"""
自動偵測欄位的 PostgreSQL Sink
"""
def __init__(
self,
name: str,
host: str,
port: int,
dbname: str,
user: str,
password: str,
table_name: str
):
super().__init__(name)
self.host = host
self.port = port
self.dbname = dbname
self.user = user
self.password = password
self.table_name = table_name
self.connection = None
def setup(self):
"""
建立資料庫連接
"""
if psycopg2 is None:
raise ImportError("psycopg2 is required")
self.connection = psycopg2.connect(
host=self.host,
port=self.port,
dbname=self.dbname,
user=self.user,
password=self.password
)
logger.info(f"Connected to PostgreSQL: {self.host}:{self.port}/{self.dbname}")
def write(self, message: Dict[str, Any]):
"""
自動偵測 message 欄位並寫入 PostgreSQL
"""
# 自動偵測欄位結構,動態生成 INSERT SQL 並執行寫入
data = message.get('value', {})
# ... 實際的欄位偵測與 SQL 執行邏輯
def close(self):
"""
關閉連接
"""
if self.connection:
self.connection.close()
logger.info("PostgreSQL connection closed")
在 Source(數據輸入)和 Sink(數據輸出)之間,我們需要一個統一的管理層來負責調度、監控和生命週期管理。這個角色就是 SimpleStreamingEngine。
┌─────────────────────┐
│SimpleStreamingEngine│ ◄── Central Manager
│ │
│ +add_source() │
│ +add_sink() │
│ + run() │
└─────────────────────┘
│
│ manages
▼
┌──────────────┐ ┌──────────────┐
│ Source │───▶│ Sink │
│ │ │ │
│ KafkaSource │ │PostgreSQLSink│
└──────────────┘ └──────────────┘
Step 1:SimpleStreamingEngine 初始化
class SimpleStreamingEngine:
def __init__(self, name: str = "simple-streaming-app"):
self.name = name
self._sources = [] # Source 列表
self._sinks = [] # Sink 列表
核心概念:
Step 2:註冊 Source 和 Sink
def add_source(self, source: BaseSource):
self._sources.append(source)
def add_sink(self, sink: BaseSink):
self._sinks.append(sink)
關鍵設計:
Step 3:核心運行邏輯
def run(self):
# 設定所有 Sink 連線
for sink in self._sinks:
sink.setup()
# 為每個 Source 設定訊息處理器,將資料送到所有 Sink
for source in self._sources:
source.message_handler = self._create_message_handler()
source.run() # 開始接收資料
核心流程:
Step 4:訊息處理器核心
def _create_message_handler(self):
def handler(message):
# 將訊息發送到所有 Sink
for sink in self._sinks:
sink.write(message)
return handler
完整資料傳遞流程詳解:
SimpleStreamingEngine 啟動時:
# SimpleStreamingEngine.run() 中
for source in self._sources:
source.message_handler = self._create_message_handler() # 注入處理器
source.run() # 啟動 Source
Source 接收資料時:
# SimpleKafkaSource.run() 中
for message in self.consumer: # 從 Kafka 拿到原始訊息
formatted_message = {
'key': message.key,
'value': message.value # 訊息內容
}
self.message_handler(formatted_message) # 呼叫 SimpleStreamingEngine 注入的處理器
處理器轉發資料:
# _create_message_handler() 返回的 handler
def handler(message): # message 就是 Source 傳來的格式化訊息
for sink in self._sinks: # 發送給每個註冊的 Sink
sink.write(message) # Sink 處理訊息
資料流向:Kafka → Source.run() → message_handler() → Sink.write()
設計精髓:SimpleStreamingEngine 透過「函數注入」讓 Source 不需要知道 Sink 的存在,達到完全解耦。
import logging
from typing import List
from .source import BaseSource
from .sink import BaseSink
logger = logging.getLogger(__name__)
class SimpleStreamingEngine:
"""
簡單的流處理引擎
"""
def __init__(self, name: str = "simple-streaming-engine"):
self.name = name
self._sources: List[BaseSource] = [] # Source 列表
self._sinks: List[BaseSink] = [] # Sink 列表
def add_source(self, source: BaseSource):
"""
添加 Source 到流處理引擎
"""
self._sources.append(source)
def add_sink(self, sink: BaseSink):
"""
添加 Sink 到流處理引擎
"""
self._sinks.append(sink)
def run(self):
"""
啟動流處理引擎,開始處理數據流
"""
# 設定所有 Sink
for sink in self._sinks:
sink.setup()
# 為每個 Source 設定訊息處理器
for source in self._sources:
source.message_handler = self._create_message_handler()
source.run() # 開始接收資料
def _create_message_handler(self):
"""
創建訊息處理器,將資料發送到所有 Sink
"""
def handler(message):
for sink in self._sinks:
sink.write(message)
return handler
到這裡,我們已經有:
現在只要把三者組裝起來,按下「啟動」,資料就會開始自動流動。
# 1. 創建 SimpleStreamingEngine
engine = SimpleStreamingEngine(...)
# 2. 創建 Kafka Source
orders_source = SimpleKafkaSource(...)
# 3. 創建 PostgreSQL Sink
pg_sink = SimplePostgreSQLSink(...)
# 4. 組裝並啟動
engine.add_source(orders_source)
engine.add_sink(pg_sink)
engine.run() # 開始處理:Kafka → PostgreSQL
今天我們深入了解了 Speed Layer 的核心實作:
通過 Source-Sink-SimpleStreamingEngine 的架構設計,我們建立了:
一開始系統運作正常,Consumer 順利處理訂單數據。但當遇到高峰流量時:
下一篇我們將探討這些 Speed Layer 效能挑戰,以及如何透過各種優化技術來解決高吞吐量場景下的問題。

 iThome鐵人賽
iThome鐵人賽